In this tutorial you learn how to
- load datasets, e.g., the SELTO datasets
- how to use pyvista plotting
- work with datasets
- get dataloaders from datasets
- create custom datasets
The ledge problem that we created manually by hand in the last tutorial is actually part of a dataset, the so-called "Basic dataset". This dataset contains examples of TO problems that we found in the literature on 3d topology optimization.
We can reproduce our ledge problem by importing the BasicDataset class and calling the "ledge()" function:
from dl4to.datasets import BasicDataset
problem = BasicDataset(resolution=40).ledge(force_per_area=-1.25e6)
Note that the force is a bit different than in the previous example, because here ledge gets force_per_area as input, whereas in the last tutorial it was force_per_volume.
The Basic dataset contains several other TO problems, e.g., including the classical cantilever problem. For more information on that we refer to the documentation of the Basic dataset class.
If you have read our SELTO paper [1], then you know that we have published two large three-dimensional datasets with almost $10.000$ samples in total. The two datasets are called "disc" and "sphere". Furthermore, they can both be divided into two subsets with different load cases, so we in fact even have four datasets to work with! We call these subsets "simple" and "complex", i.e., we refer to them as "disc simple", "disc complex", "sphere simple" and "sphere complex".
You can see the specifications of our SELTO datasets in the table below:

All four datasets are already split into training and validation subsets. Let's start with loading the validation dataset of "disc simple". The dataset will be downloaded from Zenodo [2], so you need to specify a root where the dataset should be saved:
from dl4to.datasets import SELTODataset
dataset = SELTODataset(root='/localdata/dl4to_dataset/',
name='disc_simple',
train=False)
We can print basic information on the current dataset via dataset.info():
dataset.info()
All our datasets inherit from "torch.utils.data.Dataset". so if you know PyTorch you can work with them the way that you are used to.
We can check if the dataset is indeed $200$ samples large, like the above table claims:
len(dataset)
If you want to use the full (combined) disc dataset, then you can load both "disc simple" and "disc complex" individually and simply add them up with the "+" sign.
The SELTO datasets contain not only problems, but also a ground truth for each problem. We can access the first problem in the dataset as follows:
problem, solution = dataset[0]
Plotting of the problem object explains why this dataset is called disc: The design space has the shape of a flat disc. Analogously, the design shape of the sphere datasets has the shape of a semi sphere.
Note: Please change the argument display to display=True if you run the experiments on your machine.
camera_position = (0, 0.06, 0.12)
problem.plot(camera_position=camera_position,
display=False)
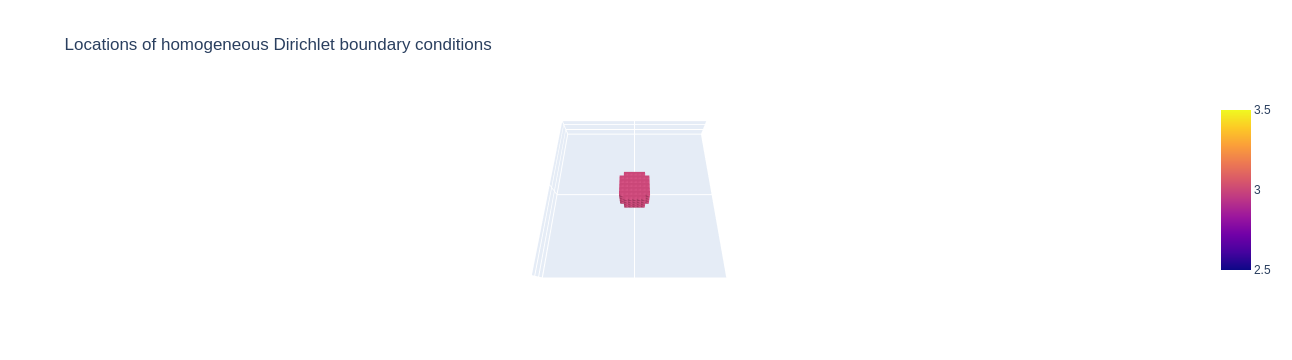

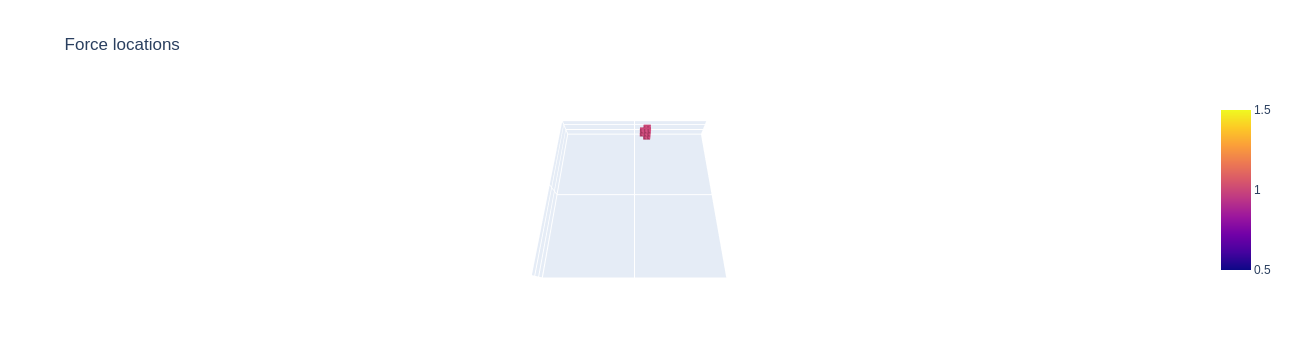

We also observe that this problem has a load case of only one single point of attack. This is the case with the "simple" datasets. If we had chosen the "disc complex" dataset above, then we would have two individual points of attack.
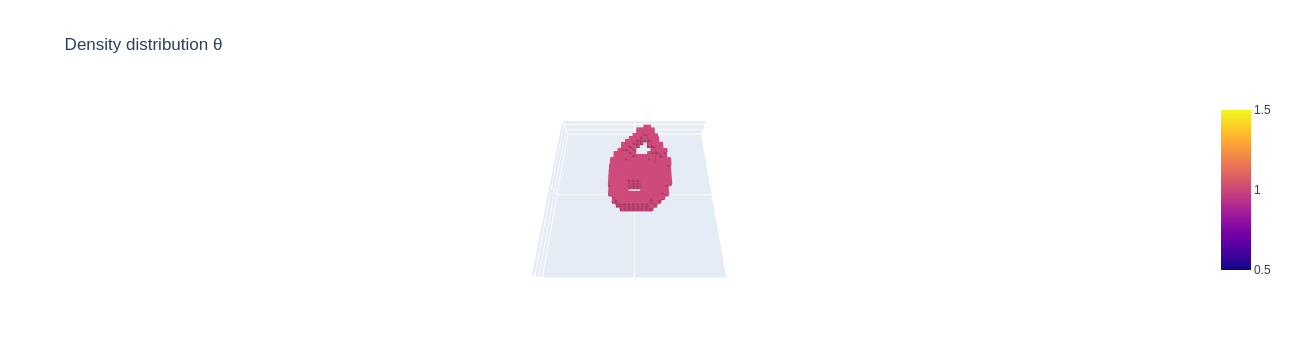
The ground truth solution to the problem looks as follows:
solution.plot(camera_position=camera_position,
display=False)
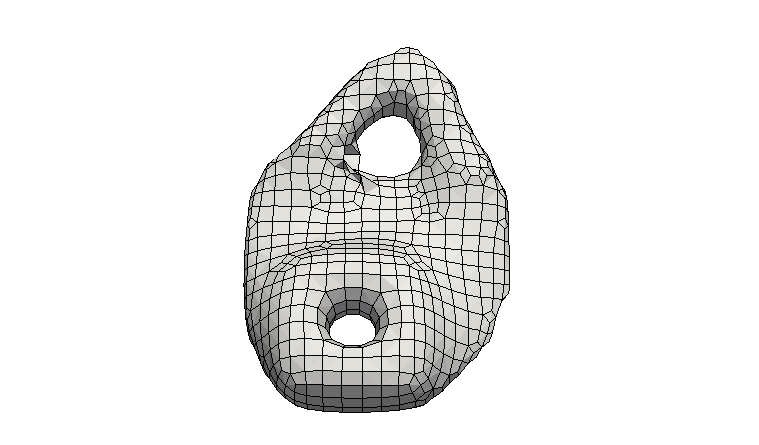
As an alternative to the standard plotly plotting interface it is also possible to use pyvista. Pyvista plotting may lead to better looking visualizations than plotly. This is mainly due to the fact, that pyvista integrates Taubin smoothing [3], which is a volume-preserving smoothing algorithm. However, the pyvista interface also has its downsides: In our experiments we found that only the backend pythreejs worked for us. This backend unfortunately currently does not support several basic functionalities. This includes for instance the display of color bars and plot titles as well as the option to save generated plots. Therefore, the plots need to be saved via manual screenshots. We still decided to leave pyvista a part of the DL4TO library, since the visualizations may be better looking for publications than the default plotly interface. it is possible that the missing features will be added in the future, if pyvista adds them to their pythreejs backend or we somehow manage to make a different backend work.
We can use pyvista for plotting by specifying use_pyvista=True and we can set the number of Taubin smoothing iterations via the parameter smooth_iters:
solution.plot(camera_position=camera_position,
use_pyvista=True,
smooth_iters=100,
window_size=(600,600),
display=False)
Note: It looks like pyvista has stopped support of the pythreejs backend that we use for the plotting. Please consider downgrading:
pip install pyvista==0.38.1
It is possible that plotting using pyvista is still not working for you, as some users have recently pointed out. Unfortunately I have not yet found a fix for that, since it seems to be an issue on behalf of pyvista. Nonetheless, plotting using the aforementioned plotly backend should still work. If the problem occurs for you and you find any workaround or fix for this, I would be very grateful if you could let me know!
Since all datasets inherit from the PyTorch Dataset class, we can easily use PyTorch dataloaders. We implemented a function that makes it even easier for you:
from dl4to.utils import get_dataloader
dataloader = get_dataloader(dataset, batch_size=64, shuffle=True)
type(dataloader)
This dataloader object automatically shuffles the dataset if desired and divides it into batches. If you prefer to use only a single batch which has the size of the full dataset, then you can do this by specifying "batch_size=-1".
Let's iterate over a dataloader and check if the sizes of each batch:
for problems, solutions in dataloader:
print(len(problems))
There are less than $64$ samples in the last batch because there were not enough samples left in the dataset to make up the full batch size.
The easiest way to create a dataset is to create it from a list. This list either contains only problems or tuples of problems and ground truths. You can then turn that list into a TopoDataset:
from dl4to.datasets import TopoDataset
my_list = [] # you can fill this list with either problems or with tuples (problem, solution)
dataset = TopoDataset(my_list)
You can save and load datasets just like regular PyTorch objects via torch.save(dataset, "dataset.pt") and dataset = torch.load("dataset.pt").
[1] Dittmer, Sören, et al. "SELTO: Sample-Efficient Learned Topology Optimization." arXiv preprint arXiv:2209.05098 (2023).
[2] Dittmer, Sören, et al. "SELTO Dataset". Zenodo. https://doi.org/10.5281/zenodo.7781392 (2023)
[3] Taubin, Gabriel. "Curve and surface smoothing without shrinkage." Proceedings of IEEE international conference on computer vision. IEEE, 1995.